이 포스트에서는 Reinforcement Learning을 효과적으로 수행할 수 있도록 intrinsic curiosity reward를 사용하는 아이디어를 제시한 Curiosity-driven Exploration by Self-supervised Prediction에 대해 소개한다.
Introduction
Curiosity-driven Exploration by Self-supervised Prediction 논문은 강화학습에서 효과적인 학습을 수행하기 위해 intrinsic reward인 curiosity 개념을 도입해 사용하는 방법을 보인다. 이 논문이 획기적인 이유는 강화학습의 영원한 숙제인 exploration vs exploitation dilemma 뿐만 아니라 비슷하지만 다른 새로운 환경에도 적용 가능하도록 하는 generalization 문제를 모두 해결했기 때문이다. 심지어 environment에 의한 reward 없이도 적절한 exploration을 유도할 수 있는 굉장히 강력한 모델이다. 이 포스트에서는 이 논문에 대해 자세히 소개하려 한다. 아래는 실제 환경에서 environment에 의한 reward 없이 exploration을 수행하는 모습이다.

 Fig 1. Discovering how to play without extrinsic reward.
Fig 1. Discovering how to play without extrinsic reward.(Image source: Github pathak22/noreward-rl.)
What is intrinsic reward
강화학습 알고리즘은 total rewards(보상)를 최대화하는 policy(정책)를 학습하는 것을 목표로 한다. agent가 environment의 특정 state $s$에서 policy $\pi$에 의해 action $a$를 수행하면 reward $r$을 획득할 수 있다. 이때 획득한 reward $r$을 바탕으로 agent의 action $a$를 결정하는 policy $\pi$를 update할 수 있다.
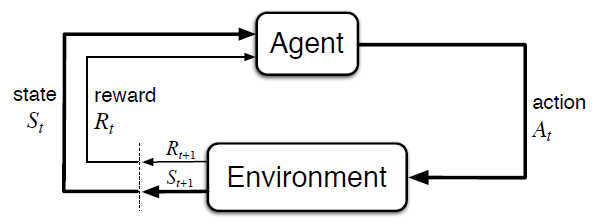 Fig 2. The agent–environment interaction in a Markov decision process.
Fig 2. The agent–environment interaction in a Markov decision process.
(Image source: Sec. 3.1 Sutton & Barto (2017).)
policy $\pi$를 효과적으로 update하기 위해서는 reward가 끊임없이 주어져야한다. 주어진 데이터가 많을 수록 더 좋은 결과를 얻을 수 있기 때문이다. 그러나 실제 환경은 다르다. agent가 action을 수행했다고 해서 반드시 reward가 제공되지는 않는다. 아니, 오히려 reward가 제공되는 경우는 극히 드물다. 어떤 특정 task를 성공적으로 수행해야 reward가 제공된다고 할 때 그 task를 수행하기가 너무 어렵다면 당연히 reward를 획득하는 것도 어렵다. 즉, 그 task를 성공적으로 수행하기 전까지는 reward의 변화가 없는 셈이다. 강화학습에서는 이러한 환경을 sparse environment라고 부른다.
Intrinsic Motivation - Curiosity
원래 강화학습에서는 policy $\pi$가 제대로 학습되지 않았을 때 environment의 특정 goal state에 도달하기 위해서는 랜덤성에 의존할 수 밖에 없었다. 이러한 방식은 simple environment를 제외하고는 효과적이지 못하다. agent의 exploration을 랜덤성에만 의존하지 않고 보다 효과적으로 이끌기 위해 제안된 아이디어 중 하나가 바로 intrinsic reward의 활용이다. 아래는 reward에 대한 2가지 구분이다.
- extrinsic reward - environment에 의해 직접 획득한 reward
- intrinsic reward - motivation과 같이 agent에게 내제된 reward로 environment로부터 직접적으로 얻지 않음
실제 인간을 생각해보자. 인간은 매우 sparse한 environment에서 살고 있다. 강화학습처럼 인간은 대부분 수천, 수만번 동일한 행동을 수행해 그에 해당하는 보상을 획득하지 못한다. 그런 상황 속에서도 인간은 최적의 reward를 획득하기 위해 시도한다. 이것이 가능한 근본적 이유는 무엇일까? 3살짜리 어린아이를 생각해보자. 3살짜리 어린아이를 혼자 두었다고 할 때 따로 학습을 시키지 않았음에도 스스로 잘 놀며 이로 인해 행복이나 즐거움 같은 보상을 획득한다. 이것이 가능한 이유는 3살짜리 아이가 내재되어있는 동기부여인 호기심(curiosity)을 이용하기 때문이다. 인간의 근본적인 감정인 curiosity를 이용해 environment를 탐구하고 새로운 state를 발견한다.
위 아이디어를 바탕으로 강화학습에서도 비슷하게 intrinsic motivation인 curiosity를 이용하였다. 이 논문에서 curiosity는 2가지 용도로 사용된다.
- agent가 새로운 지식을 추구하기 위해 environment를 탐색하도록 돕는다.
- 미래의 scenario에 도움이 될 수 있는 스킬을 학습하게 한다.
intrinsic reward를 활용할 시 sparse environment에서 굉장히 강력한 퍼포먼스를 보인다.
Problem
intrinsic reward를 활용하는 방법은 크게 아래와 같이 구분된다.
- agent가 새로운 state를 explore 하도록 한다.
- 행동 결과를 예측하는 능력을 바탕으로 행동을 수행하여 error와 불확실성을 줄인다.
위 방법을 적용할 때 아래와 같은 문제들이 발생한다.
- 이미지와 같은 high-dimensional continuous state space에서 “novelty”나 prediction error/uncertainty를 측정하는 모델을 구축하는 것은 어렵다.
- environment에 noise가 작용할 경우 agent-environment system의 확률을 다루는 것은 어렵다. noise가 environment에 별다른 영향을 미치지 않지만 agent는 완전히 새로운 state로 인식할 수 있다.
- 물리적, 시각적으로는 다르지만 기능적으로 비슷한 환경에 generalization를 적용하는 것이 어렵다. 이는 특히 매우 큰 환경에서는 굉장히 중요한 문제이다.
위 문제들에 대한 해결책으로 agent가 특정 state에서의 행동 결과를 예측하긴 어렵지만 배울만한 가치가 있을 때만 reward를 제공하는 것이다. 하지만 이러한 learnability를 추정하는 것 역시 상당히 어려운 문제이다.
Key insight
learnability를 추정하기 위한 environment 변화에 대한 예측 시, 위에서 제시한 문제들을 피하기 위해 agent의 action 때문에 environment가 변할 가능성이 있거나 agent에게 영향을 미칠 수 있는 environment의 변화만 예측한다. 그 외 나머지 요소는 모두 버린다. 이를 위해 굉장히 민감한 raw space(e.g. pixels)가 아닌 agent에 의해 수행된 action과 관련된 정보만을 표현하는 feature space를 학습한다.
Curiosity-Driven Exploration
agent는 curiosity-driven intrinsic reward signal을 생성하는 reward generator와 intrinsic reward를 최대화하는 action들의 sequence를 구하는 policy로 구성된다. 또한 아주 가끔씩(sparse environment이기 때문에) extrinsic reward를 획득한다. time step $t$에서의 intrinsic curiosity reward를 $r_t^i$, extrinsic reward를 $r_t^e$라고 할 때 policy는 $r_t = r_t^i + r_t^e$를 최대화하는 방향으로 학습된다.
신경망 매개변수가 $\theta_P$일 때 policy $\pi(s_t; \theta_P)$에 대해 $\theta_P$는 아래와 같이 reward의 expected sum을 최대화하는 방향으로 학습된다.
\[\max_{\theta_P}\mathbb{E}_{\pi(s_t; \theta_P)}[\textstyle\sum_tr_t]\]Prediction error as curiosity reward
curiosity reward $r^i$는 agent의 environment에 대한 지식의 prediction error를 기반으로 디자인된다. 문제는 환경을 어떻게 예측할 것인가이다. Problem에서 언급했듯이 이미지와 같은 raw pixel space를 예측하는 것은 굉장히 부적절하다. 이는 굉장히 민감한 환경이기 때문이다. agent에게 아무런 영향도 미치지 못하지만 pixel이 조금만 변경되더라도 prediction error는 여전히 큰 상태일거고 agent는 이로인해 쓸모없는 target에 계속 curiosity를 가지는 함정에 빠지게 될 것이다. 따라서 Key insight에서 언급했듯이 agent에게 유의미한 정보만을 표현하는 feature space를 학습해야한다. 이에 따라 먼저 agent의 관찰을 다음과 같은 3가지 케이스로 나눈다.
- agent에 의해 컨트롤 될 수 있는 것들
- agent가 컨트롤 할 수는 없지만 agent에게 영향을 미칠 수 있는 것들
- agent에 의해 컨트롤 되지 않고 영향도 못미치는 것들
curiosity에 대해 좋은 feature space는 1과 2를 모델링해야하며 3에 의해 영향을 받지 않아야 한다.
Intrinsic Curiosity Module
이 논문에서 feature space로 인코딩하고 intrinsic curiosity reward를 제공하기 위한 메커니즘인 Intrinsic Curiosity Module(ICM)을 소개한다. ICM은 크게 inverse dynamics model과 forward dynamics model로 구분되며 각각은 서로 다른 신경망이다.
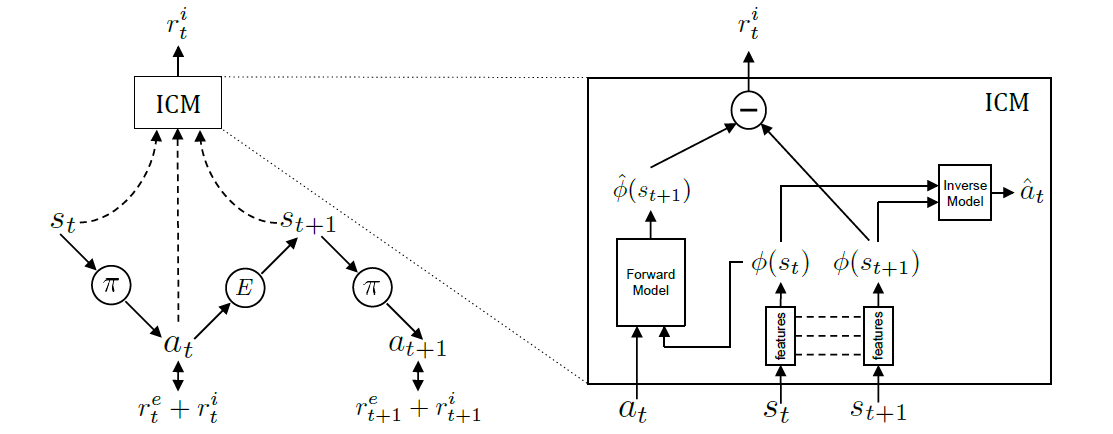 Fig 3. Intrinsic Curiosity Module (ICM).
Fig 3. Intrinsic Curiosity Module (ICM).
(Image source: Curiosity-driven Exploration by Self-supervised Prediction.)
inverse dynamics model은 2개의 서브 모듈로 구성된다. 첫번째 서브 모듈은 raw state $s_t$와 $s_{t+1}$를 feature vector $\phi(s_t)$와 $\phi(s_{t+1})$로 인코딩한다. 이 논문에서는 raw pixel을 변환하기 위해 CNN을 사용하였다. 두번째 서브 모듈은 $\phi(s_t)$와 $\phi(s_{t+1})$을 입력 받아 action $a_t$의 추정치인 $\hat{a}_t$를 예측한다. 이 논문에서는 fully connected layer에 위 feature vector가 concatenated된 single feature vector를 입력으로 사용하였다. Markov Decision Process(MDP)에 의하면 $s$에서 $a$에 의해 $s’$로 전이된다. 그런데 이 model은 현재 상태 $s$와 그 결과인 $s’$이 주어져 있을 때 역으로 원인인 $a$를 추정하기 때문에 inverse model이다. 두 서브 모듈에 대한 신경망의 learning function $g$는 아래와 같다.
\[\hat{a}_t = g\Big(s_t, s_{t+1}; \theta_I\Big)\]신경망 매개변수 $\theta_I$는 $\hat{a}_t$와 $a_t$에 대한 손실 함수 $L_I$를 최소화하는 방향으로 최적화된다. 만약 $a_t$가 discrete하다면 $g$의 output은 soft-max distribution이다.
\[\min_{\theta_I}L_I(\hat{a}_t, a_t)\]이를 통해 inverse model은 state에서 agent의 action과 관련있는 feature를 추출할 수 있다.
다음은 forward dynamics model이다. 이 model에서는 $a_t$와 $\phi(s_t)$를 입력으로 받아 $\phi(s_{t+1})$의 추정치인 $\hat{\phi}(s_{t+1})$을 예측한다. 이 논문에서는 2개의 fully connected layer로 구성된 신경망에 $\phi(s_t)$와 $a_t$가 concatenated된 vector를 입력한다. 이 model은 현재 상태 $s$와 원인인 $a$가 주어져있고 그 결과인 $s’$을 예측하고 있기 때문에 forward model이다.
\[\hat{\phi}(s_{t+1}) = f\Big(\phi(s_t), a_t; \theta_F \Big)\]신경망 매개변수 $\theta_F$는 손실 함수 $L_F$를 최소화하는 방향으로 최적화된다.
\[L_F\Big(\phi(s_t), \hat{\phi}(s_{t+1})\Big) = \dfrac{1}{2}\lVert \hat{\phi}(s_{t+1}) - \phi(s_{t+1}) \rVert_2^2\]손실함수 $L_F$의 입력이 왜 $\phi(s_{t+1})$이 아닌 $\phi(s_t)$인지는 잘 모르겠음. 이유 알려주시면 ㄳ.
Prediction error as curiosity reward에서 언급했듯이 intrinsic curiosity reward $r_t^i$는 agent의 environment에 대한 지식의 prediction error이다. environment에 대한 지식은 raw space $s$가 아닌 agent에게 유의미한 정보만을 표현하는 인코딩된 feature vector $\phi(s)$를 사용한다. 그 수식은 아래와 같다.
\[r_t^i = \dfrac{\eta}{2}\lVert \hat{\phi}(s_{t+1}) - \phi(s_{t+1}) \rVert_2^2\]이때 $\eta > 0$는 scaling factor이다. 위 수식을 보면 forward model이 예측한 feature $\hat{\phi}(s_{t+1})$와 실제 feature $\phi(s_{t+1})$의 prediction error가 curiosity로 사용된다. 호기심이라는것 자체가 내가 예상한 것과 전혀 다른 결과가 나올 때 보통 강하게 느껴지기 때문에 이러한 수식이 적용된 것이라고 판단된다. 또한 forward model의 손실 함수 역시 prediction error인데 이 이유는 그 상태에 대해 어느정도 알게 되었기 때문에 그 상태에 대한 관심이 떨어져서이다. 관심이 떨어지면 호기심 역시 줄어든다. 어쩌면 인간과 굉장히 유사한 메커니즘으로 볼 수 있다.
inverse model은 environment의 feature를 인식하고 추출하며 forward model은 feature에 대한 prediction을 진행한다. 이 prediction error로 curiosity intrinsic reward가 생성된다. 이때 각 model의 손실함수는 함께 최적화된다.
위에서 본 내용을 전체적으로 종합하면 최적화 문제는 아래와 같다.
\[\min_{\theta_P, \theta_I, \theta_F} \bigg[ -\lambda \mathbb{E}_{\pi(s_t; \theta_P)}[\textstyle\sum_tr_t] + (1-\beta)L_I + \beta L_F \bigg]\]$\lambda > 0$인 scalar로 intrinsic reward signal 학습의 중요도 대비 policy gradient loss의 중요도를 의미한다. policy gradient는 원래 reward를 maximize하는 방향으로 policy $\pi$가 업데이트 되지만 $-$ 부호를 붙여 minimize 시키게 만들었다. $0 \leq \beta \leq 1$는 inverse model loss와 forward model loss 사이의 비중이다. 이 논문에서는 $\beta = 0.2$, $\lambda = 0.1$의 값을 사용하였다.
Summary
지금까지 ICM에 대해 알아보았다. ICM은 intrinsic curiosity reward를 통해 agent가 유의미한 exploration을 할 수 있도록 함으로써 exploration vs exploitation dilemma를 해결하였다. 또한 sensory한 high-dimensional observation space를 agent에게 유의미한 feature space로 인코딩함으로써 generalization 문제를 해결하였다.
이 논문에서는 VizDoom과 Super mario Bros 게임에서 각각 실험을 진행하였다. 실험에서는 A3C + ICM과 vanilla A3C를 비교하였는데 상당히 유의미한 성능 차이를 보였다. 또한 A3C + ICM과 A3C + ICM(pixels - no feature encoding)의 비교 결과 역시 유의미만 차이를 보였다. 이는 특히 generalization 부분에서 상당한 차이를 발생시켰다. 이 논문이 더 대단한 점은 extrinsic reward 없이 intrinsic reward 만으로도 agent가 environment를 잘 탐색하도록 만들었다는 점이다. 자세한 실험 결과는 논문을 직접 참조하길 바란다.
References
[1] Pathak et al. Curiosity-driven Exploration by Self-supervised Prediction.
[2] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction; 2nd Edition. 2017.
[3] Github. pathak22/noreward-rl.