이 포스트에서는 RL에서 environment에 대한 지식을 완전히 알 수 없을 때 experience를 통해 문제를 해결하는 Monte Carlo methods를 소개한다.
Introduction
Monte Carlo (MC) methods는 반복된 random sampling을 통해 numerical한 근사해를 얻는 방법으로 일종의 simulation 기법이다. Reinforcement Learning (RL)에서 environment에 대한 지식을 완전히 알지 못할 때 MC methods는 굉장히 유용하다. DP에서와 같이 어떤 state에서 next state로의 transition에 대한 정보를 사전에 알 필요 없이 model은 단순히 transition을 sampling하기만 하면 된다. agent는 sampling된 state, action, reward와 같은 experience의 sequence를 바탕으로 sample return들에 대해 평균을 냄으로써 RL problem을 해결한다.
MC methods는 일반적으로 experience를 episode 단위로 나누어 적용된다. 따라서 모든 episode는 반드시 terminal state가 존재하는 episodic task여야 한다. MC methods 역시 Generalized Policy Iteration (GPI)를 따르며 한 episode가 끝날 때마다 policy evaluation과 policy improvement가 수행되는 step-by-step (online)이 아닌 episode-by-episode 방법이다.
Monte Carlo Prediction
먼저 value function을 추정하는 policy evaluation 혹은 prediction에 대해 알아보자. state value의 가장 간단한 정의는 state $s$에서 시작하여 policy $\pi$를 따를 때 얻을 수 있는 expected return이다.
\[v_\pi(s) \doteq \mathbb{E}_\pi[G_t \ \vert \ S_t = s]\]Monte Carlo methods는 episode 단위로 수행되기 때문에 먼저 policy $\pi$를 따라 episode를 생성한다. 그 후 episode 내의 experience로부터 위 정의를 그대로 따라 방문된 state에 대한 value function을 추정한다.
같은 episode 내에서 동일한 state가 여러번 방문될 수 있다. 이때 크게 2가지 방법으로 처리한다.
- first-visit MC method
- every-visit MC method
first-visit MC method는 한 episode 내에서 state $s$를 처음 방문했을때의 return만 그 state의 average return에 반영한다. 반면 every-visit MC method는 한 episode 내에서 state $s$를 방문할때마다 그때의 return을 모두 average return에 반영한다. 이 포스트에서는 first-visit MC method만 고려할 계획이다.
MC method를 backup diagram으로 나타내면 아래와 같다. 빨간색 영역이 한 episode이다.
 Fig 1. MC backup diagram.
Fig 1. MC backup diagram.
(Image source: Robotic Sea Bass. An Intuitive Guide to Reinforcement Learning.)
Dynamic Programming (DP)에서는 가능한 모든 transition을 고려했다면 MC methods에서는 sampling된 한 episode만 고려하고 있음을 알 수 있다. 또한 DP에서는 one-step transition만을 고려했지만 MC methods에서는 episode가 끝날 때까지의 모든 transition을 고려한다.
Monte Carlo Estimation of Action Values
Monte Carlo Prediction에서 소개한 방법은 value-based 방법이다. 그러나 이 방법은 policy를 개선할 때 큰 문제가 발생하는데 결국 environment에 대한 지식인 state transition과 관련된 probability distribution을 알아야 한다.1 policy improvement를 통해 new greedy policy $\pi’$을 획득한다고 할 때 수식은 아래와 같다.
\[\pi'(s) \doteq \underset{a}{\arg\max} \ q_\pi(s, a)\]new policy를 결정하는 방법은 간단하다. 그 state에서의 action value만 알고 있으면 된다. 문제는 action value를 구할 때 발생한다. action value $q_\pi(s, a)$를 구하는 수식은 아래와 같다.
\[\begin{align} q_\pi(s,a) &\doteq \mathbb{E}[R_{t+1} + \gamma v_\pi(S_{t+1}) \ \vert \ S_t = s, A_t = a] \\ &= \sum_{s',r}p(s',r \vert s,a)\Big[r + \gamma v_\pi(s') \Big] \end{align}\]위 수식을 보면 알 수 있듯이 state value function $v_\pi$를 통해 action value $q_\pi$를 구할 때 environment dynamics $p(s’,r \vert s,a)$를 알아야만 한다. policy evaluation에서 random sampling을 통해 environment에 대한 지식 없이 state value $v_\pi(s)$를 추정할 수 있었지만, policy improvement를 수행하기 위해서는 결국 environment에 대해 알고 있어야만 하는 문제가 발생한다.
위 문제는 environment에 대해 알고 있다면 value-based MC methods를 통해서도 해결할 수 있다. 그러나 environment에 대해 알지 못한다면 다른 접근법이 필요한데, state value를 추정하는 것이 아니라 state-action pair에 대한 action value 그 자체를 추정하면 이 문제를 해결할 수 있다. action value $q_\pi$의 가장 간단한 정의는 state $s$에서 policy $\pi$에 따라 action $a$를 선택했을 때 얻을 수 있는 expected return이다.
\[q_\pi(s, a) \doteq \mathbb{E}_\pi[G_t \ \vert \ S_t = s, A_t = a]\]위 정의에 따라 action value 자체를 추정해 획득한 값으로 policy improvement를 수행하면 environment에 대한 정보가 필요 없어진다.
Monte Carlo Control
이제 Monte Carlo estimation이 optimal policy를 추정하는 policy improvement 혹은 control에 어떻게 적용될 수 있는지 알아보자. 앞서 언급했지만 MC methods 역시 GPI를 따른다. 다만 이제 policy evaluation에서 state value가 아닌 action value $q_\pi$를 추정할 것이다.
 Fig 2. GPI for action value.
Fig 2. GPI for action value.
(Image source: Sec 5.3 Sutton & Barto (2018).)
위 그림을 sequence로 나타내면 아래와 같다.
\[\pi_0 \overset{E}{\longrightarrow} q_{\pi_0} \overset{I}{\longrightarrow} \pi_1 \overset{E}{\longrightarrow} q_{\pi_1} \overset{I}{\longrightarrow} \pi_2 \overset{E}{\longrightarrow} \cdots \overset{I}{\longrightarrow} \pi_\ast \overset{E}{\longrightarrow} q_\ast\]위에서 $\overset{E}{\longrightarrow}$는 policy evaluation, $\overset{I}{\longrightarrow}$는 policy improvement를 나타낸다.
policy evaluation은 앞서 Monte Carlo Prediction에서 소개한 방식과 동일하다. 현재 policy $\pi$에 따라 state-action pair에 대한 experience를 통해 episode가 생성되고, 이 episode에 대해 관찰된 return들을 바탕으로 action value $q_\pi$를 추정한다. 그 후 계산된 action value $q_\pi$를 바탕으로 episode 내에 방문된 모든 state에 대해 policy가 개선된다. 이를 episode 단위로 반복하다 보면 optimal policy $\pi_\ast$와 optimal action value $q_\ast$를 획득할 수 있다. 즉, 아래와 같이 3가지 과정으로 요약할 수 있다.
- policy $\pi$에 따라 episode 생성
- episode 내의 experience를 바탕으로 $q_\pi$에 대한 policy evaluation
- policy improvement
다만 optimal policy와 action value로 수렴하기 위해서는 반드시 모든 state-action pair가 방문된다는 가정이 필요하다. 즉, agent는 environment에 대해 골고루 탐색해야 한다. 이는 RL에서 굉장히 일반적인 maintaining exploration 문제이다. action value를 통해 policy evaluation을 효과적으로 수행하기 위해서는 반드시 지속적인 exploration을 보장해야한다. 이 포스트에서는 이 문제에 대한 해결책으로 2가지 방법을 소개한다.
- exploring starts
- $\epsilon$-soft policy
exploring starts (ES)는 episode 시작 시 state-action pair $(s, a)$를 stochastic하게 선택하며, 이 때 모든 시작 state-action pair는 반드시 0이 아닌 확률을 가진다. 이 경우 episode의 수가 무한할 경우 모든 state-action pair가 방문됨을 보장할 수 있다.
그러나 위 방법은 특정 state에서 시작해야하는 조건이 있는 경우 유용하지 않다. 이에 대한 대안으로 각 state에서 선택할 모든 action에 대해 0이 아닌 확률을 보장하는 stochastic policy를 고려한다. 대표적으로 $\epsilon$-soft policy가 있다.
이제 각 방법을 바탕으로 한 MC methods 알고리즘을 알아보자.
Monte Carlo ES
first-visit Monte Carlo ES 알고리즘은 아래와 같다.
$\text{Algorithm: Monte Carlo ES (Exploring Starts), for estimating } \pi \approx \pi_\ast$
\(\begin{align*} & \textstyle \text{Initialize:} \\ & \textstyle \qquad \pi(s) \in \mathcal{A}(s) \text{ (arbitrarily), for all } s \in \mathcal{S} \\ & \textstyle \qquad Q(s,a) \in \mathbb{R} \text{ (arbitrarily), for all } s \in \mathcal{S}, \ a \in \mathcal{A}(s) \\ & \textstyle \qquad \textit{Returns}(s,a) \leftarrow \text{empty list, for all } s \in \mathcal{S}, \ a \in \mathcal{A}(s) \\ \\ & \textstyle \text{Loop forever (for each episode):} \\ & \textstyle \qquad \text{Choose } S_0 \in \mathcal{S}, \ A_0 \in \mathcal{A}(S_0) \text{ randomly such that all pairs have probability} > 0 \\ & \textstyle \qquad \text{Generate an episode from } S_0, A_0, \text{ following } \pi \text{: } S_0, A_0, R_1, \dots, S_{T-1}, A_{T-1}, R_T \\ & \textstyle \qquad G \leftarrow 0 \\ & \textstyle \qquad \text{Loop for each step of episode, } t = T-1, T-2, \dots, 0 \text{:} \\ & \textstyle \qquad\qquad G \leftarrow \gamma G + R_{t+1} \\ & \textstyle \qquad\qquad \text{Unless the pair } S_t, A_t \text{ appears in } S_0, A_0, S_1, A_1, \dots, S_{t-1}, A_{t-1} \text{:} \\ & \textstyle \qquad\qquad\qquad \text{Append } G \text{ to } \textit{Returns}(S_t,A_t) \\ & \textstyle \qquad\qquad\qquad Q(S_t,A_t) \leftarrow \text{average}(\textit{Returns}(S_t,A_t)) \\ & \textstyle \qquad\qquad\qquad \pi(S_t) \leftarrow \arg\max_a Q(S_t,a) \end{align*}\)
exploring starts이기 때문에 각 episode의 시작마다 모든 state-action pair의 확률이 0보다 큰 조건 하에 랜덤하게 state-action pair를 선택한다. 또한 action value $Q(S_t, A_t)$를 정의에 따라 $S_t, A_t$ pair에 대해 지금까지 획득한 return $G_t$들의 expectation으로 update한다.
Monte Carlo Control without ES
exploring starts는 쉽게 말해 랜덤 스타트로, 문제가 있는 방식이라 소개했었다. 따라서 ES를 사용하지 않고 모든 state-action pair가 방문됨을 보장하려고 한다. 이를 달성할 수 있는 일반적인 방법은 episode의 시작에서만 하는게 아니라 episode 동안 지속적으로 agent가 state-action pair를 무한히 선택할 수 있도록 보장한다. 이것을 달성하기 위한 2가지 접근법이 있다.
- on-policy methods
- off-policy methods
on-policy methods는 experience 생성에 사용되는 policy를 평가하고 개선한다. 반면 off-policy methods는 experience를 생성하는데 사용되는 policy와 평가 및 개선하는데 사용되는 policy를 분리하는 방법이다.
On-policy Monte Carlo
on-policy methods에서는 policy는 일반적으로 soft하다. soft하다는 것은 모든 $s \in \mathcal{S}$와 $a \in \mathcal{A}$에 대해 $\pi(a \vert s) > 0$는 의미이다. 즉, 모든 state-action pair에게 0이 아닌 확률을 보장한다. 이러한 soft한 policy를 GPI 과정을 거치면서 점점 deterministic한 optimal policy로 수렴한다.
위를 달성할 수 있는 가장 간단하 방법 중 하나가 $\epsilon$-greedy policy이다. $\epsilon$-greedy policy는 대부분은 action value가 최대인 action을 선택하지만 $\epsilon$의 확률로 랜덤하게 action을 선택한다. 따라서 모든 action들은 아래와 같이 선택될 확률을 가진다.
\[\pi(a \vert s) = \begin{cases} 1 - \epsilon + \dfrac{\epsilon}{\vert \mathcal{A}(s) \vert} & \text{if } a = \text{greedy} \\ \dfrac{\epsilon}{\vert \mathcal{A}(s) \vert} \qquad & \text{if } a = \text{nongreedy} \end{cases}\]$\epsilon$-greedy policy는 $\epsilon$-soft policy의 가장 대표적인 예시이다. $\epsilon$-soft policy는 모든 state와 action에 대해 $\pi(a \vert s) \geq \dfrac{\epsilon}{\vert \mathcal{A}(s) \vert}$인 policy이다.
On-policy first-visit MC methods 알고리즘을 살펴보자. policy는 $\epsilon$-greedy이다.
$\text{Algorithm: On-policy first-visit MC control (for } \epsilon \text{-soft policies), estimates } \pi \approx \pi_\ast$
\(\begin{align*} & \textstyle \text{Algorithm parameter: small } \epsilon > 0 \\ & \textstyle \text{Initialize: } \\ & \textstyle \qquad \pi \leftarrow \text{an arbitrary } \epsilon \text{-soft policy} \\ & \textstyle \qquad Q(s, a) \in \mathbb{R} \text{ (arbitrarily), for all } s \in \mathcal{S}, \ a \in \mathcal{A}(s) \\ & \textstyle \qquad \textit{Returns}(s,a) \leftarrow \text{empty list, for all } s \in \mathcal{S}, \ a \in \mathcal{A}(s) \\ \\ & \textstyle \text{Loop forever (for each episode):} \\ & \textstyle \qquad \text{Generate an episode following } \pi \text{: } S_0, A_0, R_1, \dots, S_{T-1}, A_{T-1}, R_T \\ & \textstyle \qquad G \leftarrow 0 \\ & \textstyle \qquad \text{Loop for each step of episode, } t = T-1, T-2, \dots, 0 \text{:} \\ & \textstyle \qquad\qquad G \leftarrow \gamma G + R_{t+1} \\ & \textstyle \qquad\qquad \text{Unless the pair } S_t,A_t \text{ appears in } S_0, A_0, S_1, A_1, \dots, S_{t-1}, A_{t-1} \text{:} \\ & \textstyle \qquad\qquad\qquad \text{Append } G \text{ to } \textit{Returns}(S_t,A_t) \\ & \textstyle \qquad\qquad\qquad Q(S_t, A_t) \leftarrow \text{average}(\textit{Returns}(S_t, A_t)) \\ & \textstyle \qquad\qquad\qquad A^\ast \leftarrow \arg\max_a Q(S_t, a) \\ & \textstyle \qquad\qquad\qquad \text{For all } a \in \mathcal{A}(S_t)\text{:} \\ & \textstyle \qquad\qquad\qquad\qquad \pi(a \vert S_t) \leftarrow \begin{cases} 1 - \epsilon + \epsilon / \vert \mathcal{A}(S_t) \vert & \text{if } a = A_\ast \\ \epsilon / \vert \mathcal{A}(S_t) \vert \qquad & \text{if } a \neq A_\ast \end{cases} \end{align*}\)
on-policy methods이기 때문에 episode 생성에 사용되는 policy $\pi$를 평가하고 개선한다. 이 때 $q_\pi$에 관한 $\epsilon$-soft policy는 policy improvement theorem에 의해 보장된다.2
Off-policy methods
off-policy methods는 아래와 같은 2개의 policy를 사용하는 방법이다.
- target policy
- behavior policy
target policy는 학습에 사용되는 policy로 target policy를 optimal policy로 수렴시키는 것이 목적이다. behavior policy는 behavior 혹은 experience를 생성하는 policy로 target policy에 비해 조금 더 exploratory한 policy이다.
on-policy는 일반적으로 비교적 쉬운 편이기 때문에 자주 고려된다. off-policy는 대게 더 높은 분산과 느린 수렴 속도를 가지지만 더 강력하고 general하다. on-policy는 target policy와 behavior policy가 동일한 경우로 취급할 수 있다.
조금 더 구체적으로 들어가자면 아래와 같은 과정을 거친다.
- behavior policy $b$로부터 episode 생성
- episode 내의 experience를 바탕으로 $q_\pi$에 대한 policy evaluation
- policy improvement
그런데 이상한 점이 있다. behavior policy $b$와 target policy $\pi$의 distribution은 전혀 다를 것이다. 우리가 구할 수 있는 것은 $\mathbb{E} _ b[X]$인데 어떻게 $b$로부터 생성된 episode를 가지고 $q_\pi$를 추정할 수 있을까? 이 문제를 해결하기 위해 importance sampling이라는 기법을 사용한다.
Importance Sampling
importance sampling은 다른 distribution을 따르는 sample이 주어졌을 때 목표로 하는 distribution의 expected value를 추정하는 기법이다. 대부분의 off-policy methods는 서로 다른 policy를 사용하기 때문에 importance sampling을 통해 expected value를 추정한다.
target policy와 behavior policy에 대한 trajectory의 상대적 확률에 따라 return에 가중치를 부여한다. 이를 importance-sampling ratio라고 한다. 먼저 시작 state $S_t$가 주어졌을 때 생성된 state-action trajectory가 아래와 같이 있다고 하자.
\[A_t, S_{t+1}, A_{t+1}, \dots, S_T\]이 때 임의의 policy $\pi$를 따를 때 위 trajectory의 발생 확률은 아래와 같다. 이때 $\pi$는 trajectory를 생성한 policy가 아니여도 된다.
\[\begin{align} & \text{Pr} \lbrace A_t, S_{t+1}, A_{t+1}, \dots, S_t \ \vert \ S_t, A_{t:T-1} \sim \pi \rbrace \\ & \qquad = \pi(A_t \vert S_t) p(S_{t+1} \vert S_t, A_t) \pi(A_{t+1} \vert S_{t+1}) \cdots p(S_T \vert S_{T-1}, A_{T-1}) \\ & \qquad = \prod_{k=t}^{T-1} \pi(A_k \vert S_k) p(S_{k+1} \vert S_k, A_k) \end{align}\]위 수식에서 $p$는 state-transition probability function이다. 임의의 policy가 각각 trajectory를 생성한 behavior policy $b$, expected value를 추정하려는 target policy $\pi$라고 할 때 위 trajectory의 확률을 바탕으로 importance-sampling ratio $\rho$를 구할 수 있다.
\[\rho_{t:T-1} \doteq \dfrac{\prod_{k=t}^{T-1} \pi(A_k \vert S_k) p(S_{k+1} \vert S_k, A_k)}{\prod_{k=t}^{T-1} b(A_k \vert S_k) p(S_{k+1} \vert S_k, A_k)} = \prod_{k=t}^{T-1}\dfrac{\pi(A_k \vert S_k)}{b(A_k \vert S_k)}\]이미 알고 있는 distribution은 분모, expected value를 추정할 distribution은 분자여야 한다. 위 수식의 분모, 분자에 있던 state-transition probability는 소거할 수 있다. 그 이유는 동일한 environment에서의 동일한 trajectory이기 때문에 state-transition probability는 동일하다. 결국 environment에 대한 지식은 필요 없게 된다. 오직 $b$와 $\pi$, 생성된 trajectory만 있으면 된다.
위에서 구한 importance-sampling ratio를 통해 이제 올바른 expected value를 추정할 수 있다. 이제 importance-sampling ratio를 통해 action value를 추정하는 방법을 알아보자.
Off-policy Monte Carlo via Importance Sampling
importance-sampling ratio $\rho$를 사용하면 behavior policy $b$를 따르는 episode를 통해서도 target policy $\pi$를 따르는 action value $q_\pi$를 추정할 수 있다. 아래는 $q_\pi$를 추정하는 수식이다.
\[q_\pi(s,a) = \mathbb{E}[\rho_{t:T-1}G_t \ \vert \ S_t = s, A_t = a]\]각 state-action pair에 대한 return $G_t$에 importance-sampling ratio $\rho$를 곱한 후 이 값들에 대한 expected value를 구하면 된다. 그렇다면 어떻게 expected value를 구할 수 있을까? 가장 간단한 방법은 위 value를 다 더한 뒤 개수로 나눈다. 이 방법을 ordinary importance sampling이라고 한다.3 이 방법은 unbiased하지만 높은 variance를 가진다. 따라서 biased하지만 variance가 매우 낮은 weighted importance sampling을 대안으로 활용한다. 아래는 weighted importance sampling을 활용해 추정한 action value $q_\pi$이다.
\[q_\pi(s,a) \doteq \dfrac{\sum_{t \in \mathcal{J}(s,a)} \rho_{t:T(t)-1}G_t}{\sum_{t \in \mathcal{J}(s,a)} \rho_{t:T(t)-1}}\]$\mathcal{J}(s,a)$는 state-action pair s, a가 방문된 time step $t$에 대한 집합이다. $T(t)$는 $t \in \mathcal{J}(s,a)$일 때의 termination time이다.
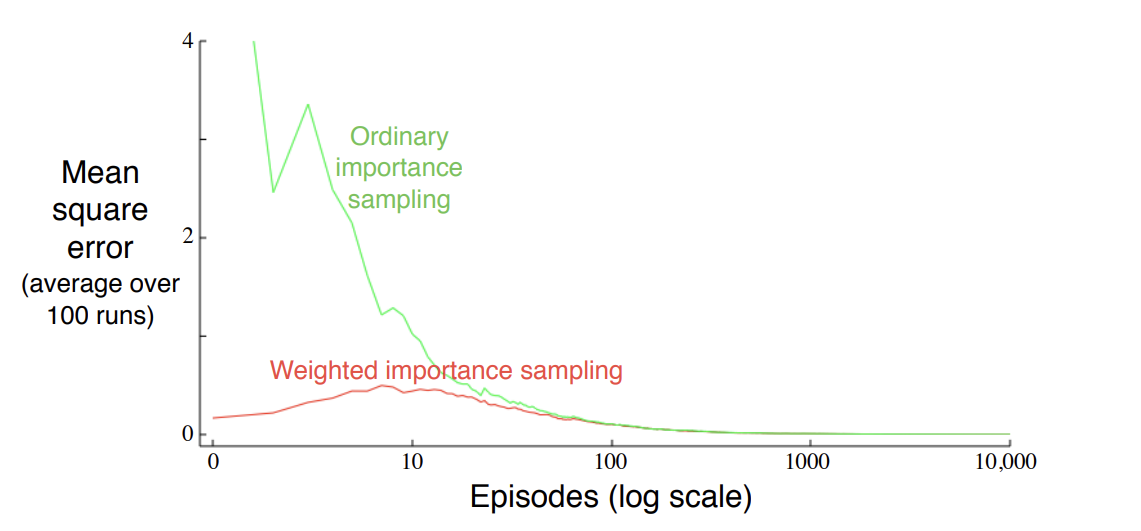 Fig 3. Ordinary importance sampling vs weighted importance sampling.
Fig 3. Ordinary importance sampling vs weighted importance sampling.
(Image source: Sec 5.5 Sutton & Barto (2018).)
위 그림은 ordinary importance sampling과 weighted importance sampling을 비교하는 그래프이다. 둘다 error가 0으로 수렴하지만 weighted importance sampling이 더 안정적임을 확인할 수 있다.
Incremental Implementation of Weighted Average
이제 off-policy Monte Carlo를 구현해보자. weighted average를 incremental 방식으로 구현해보려 한다. 먼저 $n-1$개의 return sequence $G_1, G_2, \dots, G_{n-1}$과 각각에 대응하는 weight $W_i \ (\text{e.g., } W_i = \rho_{t_i:T(t_i)-1})$가 있다고 하자. weighted average $V_n$은 아래와 같다.
\[V_n \doteq \dfrac{\sum_{k=1}^{n-1} W_k G_k}{\sum_{k=1}^{n-1} W_k}, \qquad n \geq 2\]위 $V_n$과 weight들의 cumulative sum $C_n = \sum_{k=1}^{n-1} W_k$을 유지하고 있을 때 추가적인 return $G_n$을 획득할 경우 incremental한 방식으로 $V$를 update할 수 있다. $V$에 대한 update rule은 아래와 같다.
\[V_{n+1} \doteq V_n + \dfrac{W_n}{C_n} \Big[G_n - V_n \Big] \qquad n \geq 1,\] \[C_{n+1} \doteq C_n + W_{n+1}\]위에서 $C_0 \doteq 0$이고 $V_1$은 임의의 값이다. 위 $V$를 state value라면 $v$로, action value라면 $q$로 변경하기만 하면 된다.
Off-policy MC Prediction Algorithm
이제 Off-policy MC methods 알고리즘을 보자. 여기서는 prediction 부분만 보이도록 하겠다. 한가지 중요한 사실은 target policy $\pi$와 behavior policy $b$ 모두 어떤 policy도 가능하지만 coverage를 만족해야한다. coverage란 $\pi$에 의해 선택될 수 있는 모든 action은 $b$에 의해서도 선택될 수 있어야 함을 의미한다. 즉, $\pi(a \vert s) > 0$면 $b(a \vert s) > 0$이어야 한다.
$\text{Algorithm: Off-policy MC prediction (policy evaluation) for estimating } Q \approx q_\pi$
\(\begin{align*} & \textstyle \text{Input: an arbitrary target policy } \pi \\ & \textstyle \text{Initialize, for all } s \in \mathcal{S}, \ a \in \mathcal{A}(s) \text{:} \\ & \textstyle \qquad Q(s,a) \in \mathbb{R} \text{ (arbitrarily)} \\ & \textstyle \qquad C(s,a) \leftarrow 0 \\ \\ & \textstyle \text{Loop forever (for each episode):} \\ & \textstyle \qquad b \leftarrow \text{any policy with coverage of } \pi \\ & \textstyle \qquad \text{Generate an episode following } b \text{: } S_0, A_0, R_1, \dots, S_{T-1}, A_{T-1}, R_T \\ & \textstyle \qquad G \leftarrow 0 \\ & \textstyle \qquad W \leftarrow 1 \\ & \textstyle \qquad \text{Loop for each step of episode, } t = T-1, T-2, \dots, 0, \text{ while } W \neq 0 \text{:} \\ & \textstyle \qquad\qquad G \leftarrow \gamma G + R_{t+1} \\ & \textstyle \qquad\qquad C(S_t,A_t) \leftarrow C(S_t,A_t) + W \\ & \textstyle \qquad\qquad Q(S_t,A_t) \leftarrow Q(S_t,A_t) + \frac{W}{C(S_t,A_t)}[G - Q(S_t,A_t)] \\ & \textstyle \qquad\qquad W \leftarrow W \frac{\pi(A_t \vert S_t)}{b(A_t \vert S_t)} \end{align*}\)
그런데 위 알고리즘을 보면 한가지 이상한 점이 있다. 바로 $W = 1$부터 시작하는 것이다. 우리는 앞서 Importance Sampling에서 importance-sampling ratio $\rho_{t:T-1}$는 time step $t$에서의 ratio부터 고려했었다. 즉, $\pi(A_t \vert S_t) / b(A_t \vert S_t)$를 고려했었다. 따라서 $W = \pi(A_{T-1} \vert S_{T-1}) / b(A_t \vert S_{T-1})$부터 시작해야한다. 그런데 왜 $W = 1$부터 시작하는걸까? 필자 역시 처음 공부했을 때 이러한 의문이 있었으며 어느 곳에서도 답을 찾을 수 없었다. 추후 다른 chapter를 공부하다가 그 이유를 알게 되었다. 한번 알아보자.
Importance Sampling에서 정의했던 importance-sampling ratio $\rho_{t:T-1}$는 시작 state $S_t$가 주어졌을 때 임의의 policy를 따라 생성된 state-action trajectory를 전제로 했었다.
\[A_t, S_{t+1}, A_{t+1}, \dots, S_T\]그런데 우리는 action value를 추정하고 있다. action value 추정의 전제는 state-action pair가 주어져있다는 것이다. 즉, $S_t, A_t$는 이미 주어져있기 때문에 우리가 고려해야할 state-action trajectory는 아래와 같다.
\[S_{t+1}, A_{t+1}, \dots, S_T\]따라서 action value를 추정할 떄 필요한 importance-sampling ratio는 $\rho_{t+1:T-1}$이다. Importance Sampling 파트의 trajectory가 임의의 policy 를 따를 때 발생할 확률에 위 trajectory로 대체해보면 간단히 증명할 수 있다. 위와 같은 이유로 $t = T-1$일 때 $\rho_{T:T-1} = 1$이므로, $W=1$부터 시작한다. 아래는 Reinforcement Learning: An Introduction에서 importance sampling ratio를 $t+1$부터 시작하는 이유를 설명하는 문장이다.
We do not have to care how likely we were to select the action; now that we have selected it we want to learn fully from what happens, with importance sampling only for subsequent actions.4
근데 위 문장이 Monte Carlo Methods가 아니라 n-step Bootstrapping chapter에 있었어서 다소 아쉬웠다. 이 문장을 보고 나서야 왜 $t+1$부터 시작하는지 위와 같이 이해할 수 있었다.
Summary
지금까지 Monte Carlo (MC) methods에 대해 알아보았다. MC methods는 sample episode안의 experience로부터 value function을 학습하고 optimal policy를 찾는다. MC methods는 Generalized Policy Iteration (GPI)를 따른다. MC methods는 episode-by-episode 단위로 GPI를 수행한다. action-value function을 추정할 경우 environment에 대한 지식(dynamics) 없이도 policy를 개선하는 것이 가능하다.
MC methods는 sampling을 통해 학습하는 방법이기 때문에 충분한 exploration을 보장해주어야 한다. 이에 대한 방법으로 exploring starts와 on-policy methods, off-policy methods가 있다. exploring start는 state-action pair를 랜덤하게 시작하는 방법이지만 현실과는 동떨어진 방법이다. on-policy methods는 하나의 policy로 학습과 탐색을 모두 수행한다. off-policy methods는 학습에 사용되는 target policy와 탐색에 사용되는 behavior policy로 분리하는 방법이다.
off-policy methods는 behavior policy를 따라 생성된 data로부터 target policy를 학습하는데 이 두 policy의 distribution이 다르기 때문에 문제가 발생한다. 이를 해결하기 위해 importance sampling이라는 기법을 사용해 behavior policy의 distribution으로부터 target policy의 expected value를 추정한다. 이때 ordinary importance sampling과 weighted importance sampling 2가지 방법이 존재하는데 일반적으로 분산이 낮은 weighted importance sampling이 선호된다.
MC methods는 DP와 주요한 2가지 차이점이 있다. 먼저, MC methods는 DP와 달리 environment에 대한 지식(dynamics) 없이 sample experience로부터 학습이 가능하다. 두번째는 MC methods는 bootstrap하지 않다. 즉, value function을 update할 때 DP와 달리 다른 value function의 추정치를 통해 update하지 않고 return을 직접 구해 update한다.
References
[1] Richard S. Sutton and Andrew G. Barto. Reinforcement Learning: An Introduction; 2nd Edition. 2018.
[2] Towards Data Science. Sagi Shaier. Monte Carlo Methods.
[3] 생각많은 소심남. [RL] Off-policy Learning for Prediction.
Footnotes
StackExchange. Why are state-values alone not sufficient in determining a policy (without a model)?. ↩
Reinforcement Learning: An Introduction; 2nd Edition. 2018. Sec. 5.4, p.123. ↩
Reinforcement Learning: An Introduction; 2nd Edition. 2018. Sec. 5.5, p.126. ↩
Reinforcement Learning: An Introduction; 2nd Edition. 2018. Sec. 7.3, p.171. ↩